If you follow AI news you should know that it’s basically out of training data, that extra training is inversely exponential and so extra training data would only have limited impact anyway, that companies are starting to train AI on AI generated data -both intentionally and unintentionally, and that hallucinations and unreliability are baked-in to the technology.
You also shouldn’t take improvements at face value. The latest chatGPT is better than the previous version, for sure. But its achievements are exaggerated (for example, it already knew the answers ahead of time for the specific maths questions that it was denoted answering, and isn’t better than before or other LLMs at solving maths problems that it doesn’t have the answers already hardcoded), and the way it operates is to have a second LLM check its outputs. Which means it takes,IIRC, 4-5 times the energy (and therefore cost) for each answer, for a marginal improvement of functionality.
The idea that “they’ve come on in leaps and bounds over the Last 3 years therefore they will continue to improve at that rate isn’t really supported by the evidence.
We don’t need leaps and bounds, from here. We’re already in science fiction territory. Incremental improvement has has silenced a wide variety of naysaying.
And this is with LLMs - which are stupid. We didn’t design them with logic units or factoid databases. Anything they get right is an emergent property from guessing plausible words, and they get a shocking amount of things right. Smaller models and faster training will encourage experimentation for better fundamental goals. Like a model that can only say yes, no, or mu. A decade ago that would have been an impossible sell - but now we know data alone can produce a network that’ll fake its way through explaining why the answer is yes or no. If we’re only interested in the accuracy of that answer, then we’re wasting effort on the quality of the faking.
Even with this level of intelligence, where people still bicker about whether it is any level of intelligence, dumb tricks keep working. Like telling the model to think out loud. Or having it check its work. These are solutions an author would propose as comedy. And yet: it helps. It narrows the gap between “but right now it sucks it [blank]” and having to find a new [blank]. If that never lets it do math properly, well, buy a calculator.

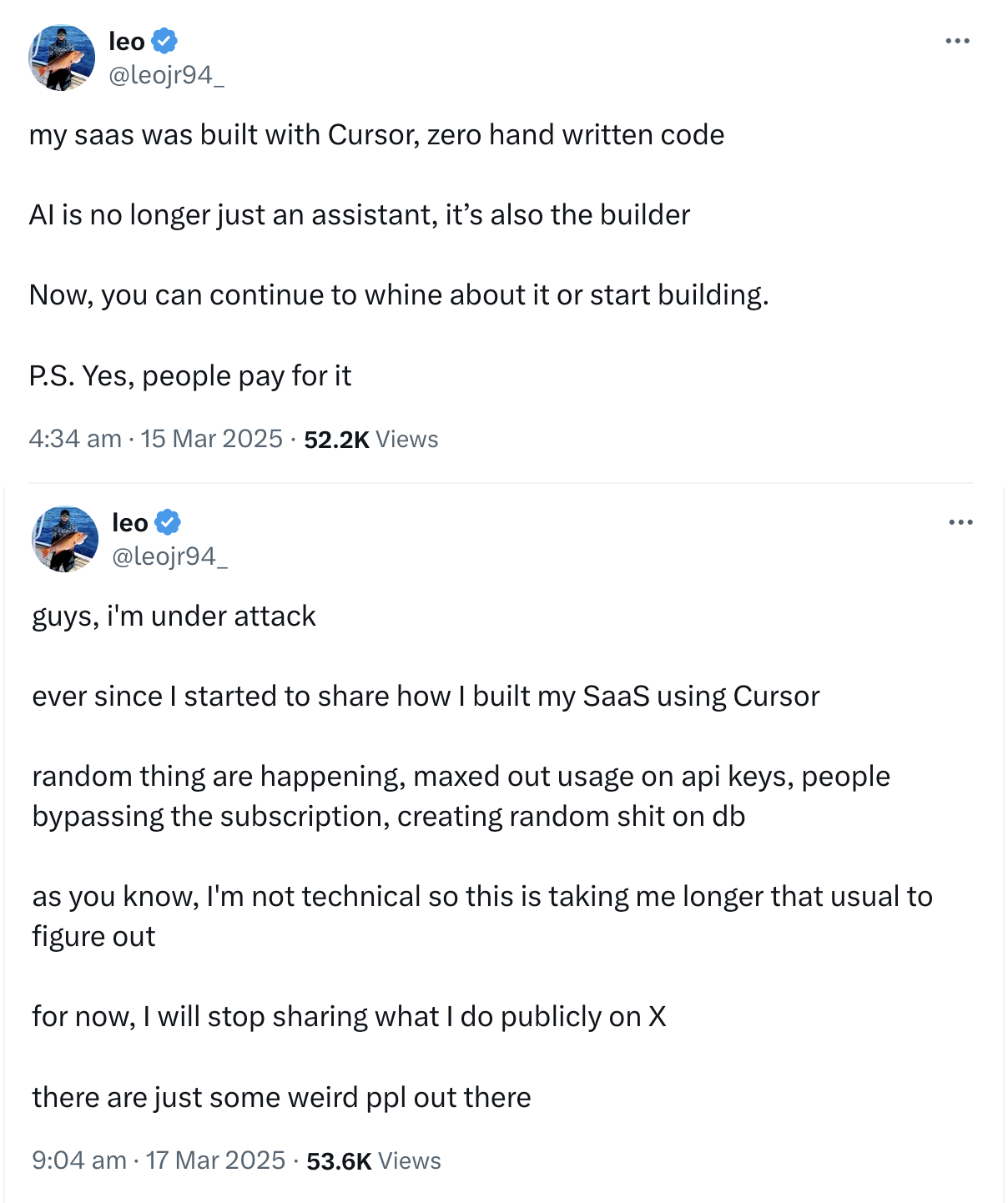{kind=link}
If you follow AI news you should know that it’s basically out of training data, that extra training is inversely exponential and so extra training data would only have limited impact anyway, that companies are starting to train AI on AI generated data -both intentionally and unintentionally, and that hallucinations and unreliability are baked-in to the technology.
You also shouldn’t take improvements at face value. The latest chatGPT is better than the previous version, for sure. But its achievements are exaggerated (for example, it already knew the answers ahead of time for the specific maths questions that it was denoted answering, and isn’t better than before or other LLMs at solving maths problems that it doesn’t have the answers already hardcoded), and the way it operates is to have a second LLM check its outputs. Which means it takes,IIRC, 4-5 times the energy (and therefore cost) for each answer, for a marginal improvement of functionality.
The idea that “they’ve come on in leaps and bounds over the Last 3 years therefore they will continue to improve at that rate isn’t really supported by the evidence.
We don’t need leaps and bounds, from here. We’re already in science fiction territory. Incremental improvement has has silenced a wide variety of naysaying.
And this is with LLMs - which are stupid. We didn’t design them with logic units or factoid databases. Anything they get right is an emergent property from guessing plausible words, and they get a shocking amount of things right. Smaller models and faster training will encourage experimentation for better fundamental goals. Like a model that can only say yes, no, or mu. A decade ago that would have been an impossible sell - but now we know data alone can produce a network that’ll fake its way through explaining why the answer is yes or no. If we’re only interested in the accuracy of that answer, then we’re wasting effort on the quality of the faking.
Even with this level of intelligence, where people still bicker about whether it is any level of intelligence, dumb tricks keep working. Like telling the model to think out loud. Or having it check its work. These are solutions an author would propose as comedy. And yet: it helps. It narrows the gap between “but right now it sucks it [blank]” and having to find a new [blank]. If that never lets it do math properly, well, buy a calculator.